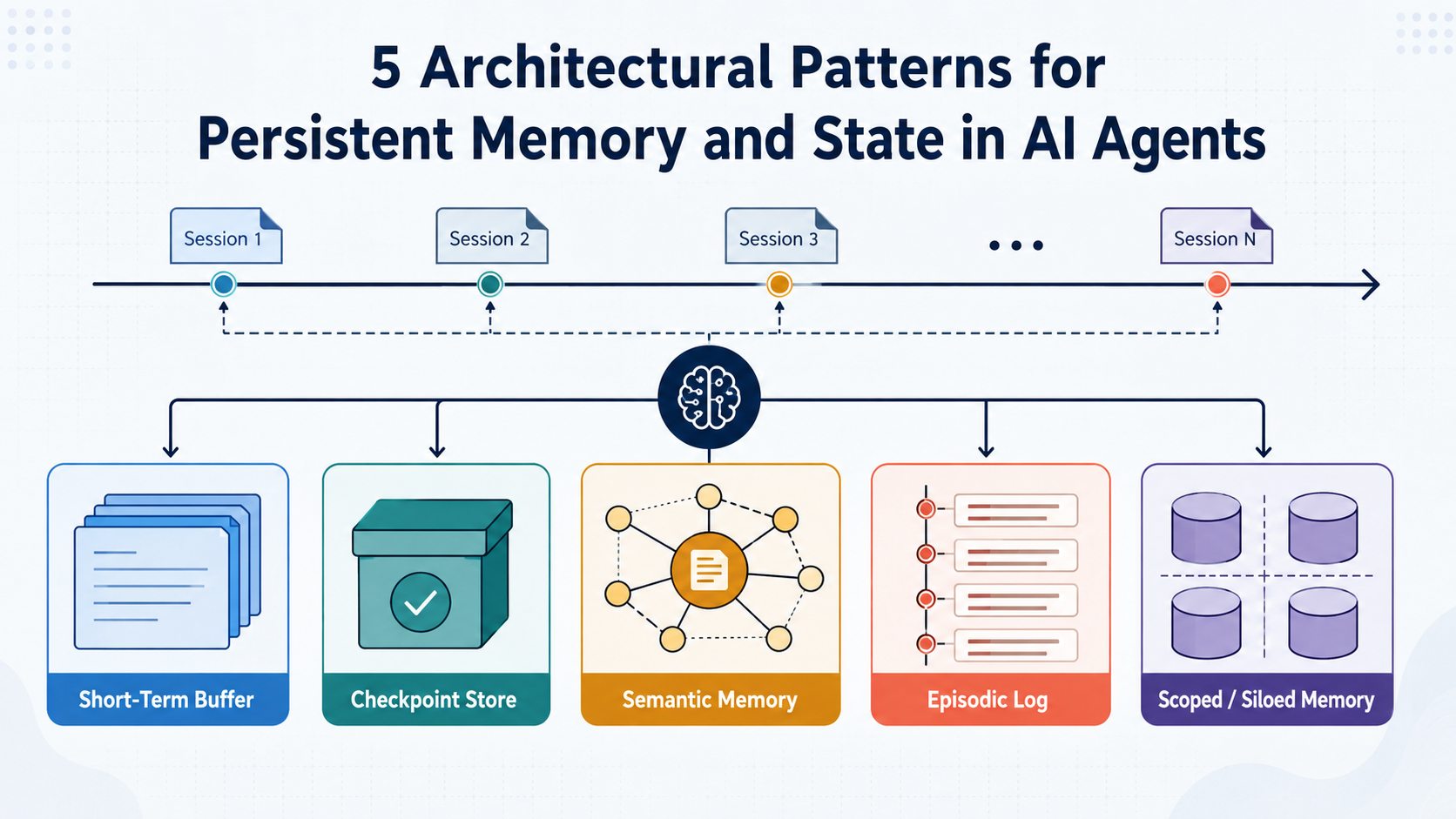
5 Architectural Patterns for Persistent Memory and State in AI Agents
Memory & State For AI Agents Building an AI agent can be tricky. Keeping it on track over a six-month deployment is incredibly hard. LLMs...
Memory & State For AI Agents Building an AI agent can be tricky. Keeping it on track over a six-month deployment is incredibly hard. LLMs...

In this article, you will learn how an agent's approach to managing state — stateless or stateful — shapes both its implementation and the deployment...

It's tempting to treat loop engineering as something invented in a single week in June, but the mechanics behind it are closer to five years old, and knowing the lineage is what separates a real understanding of the idea from just repeating the trend piece.
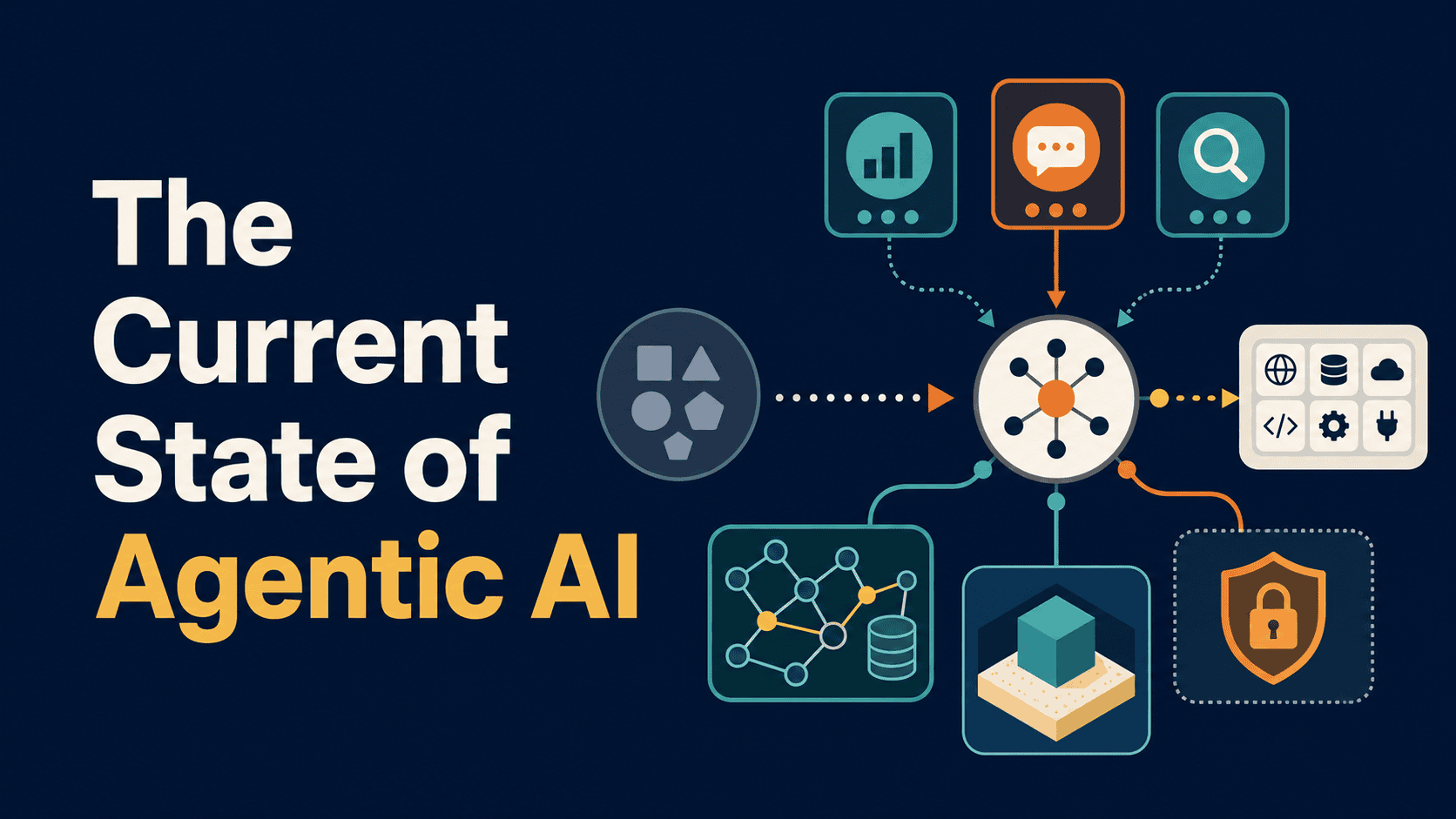
In this article, you will learn how agentic AI architecture has evolved by mid-2026, including the shift away from orchestrated reasoning loops, the rise of...
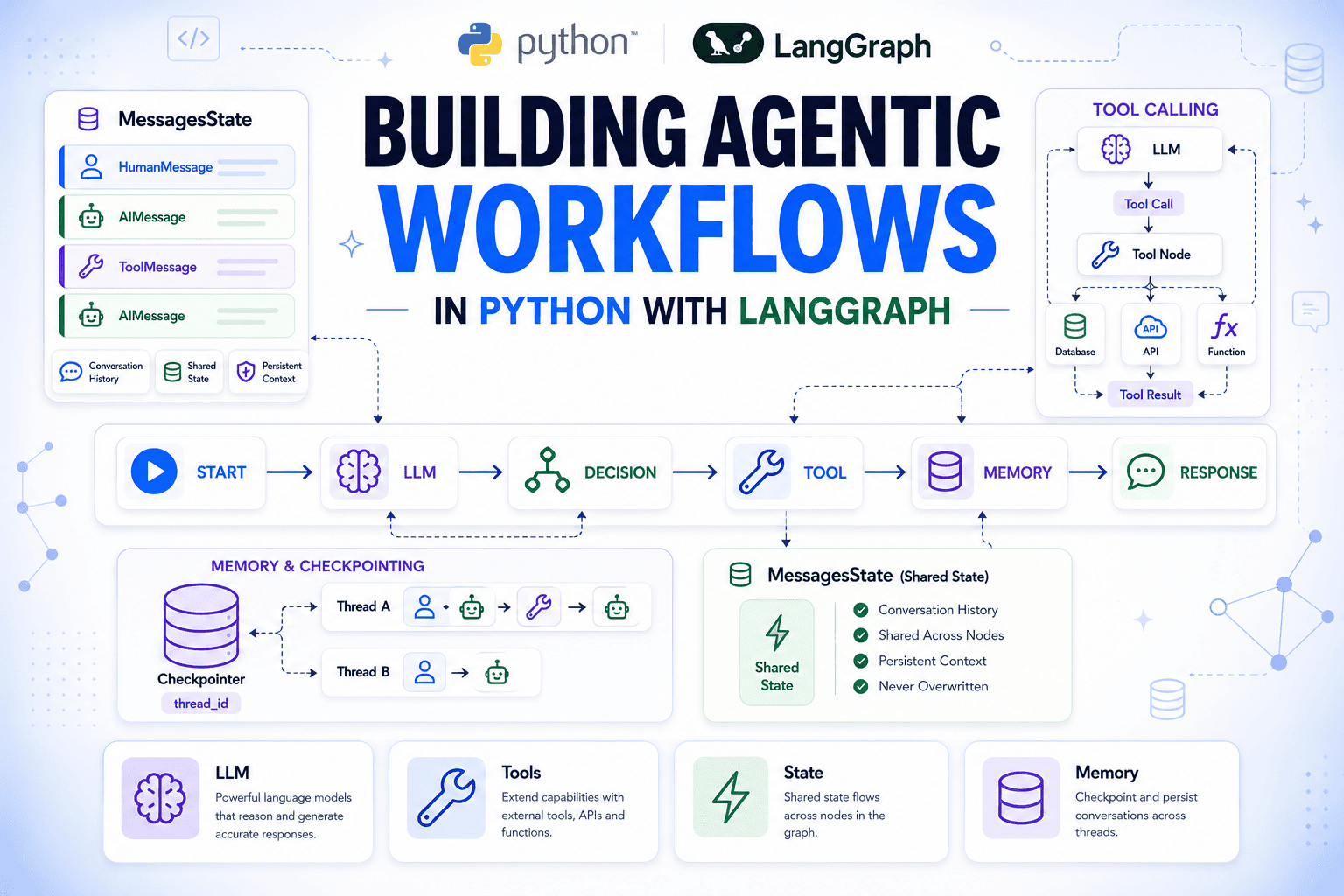
In this article, you will learn how to build a complete agentic workflow in Python with LangGraph, from a single model call to a tool-using...

In this article, you will learn what prompt injection and tool misuse are in the context of agentic AI systems, and which defense strategies experts...
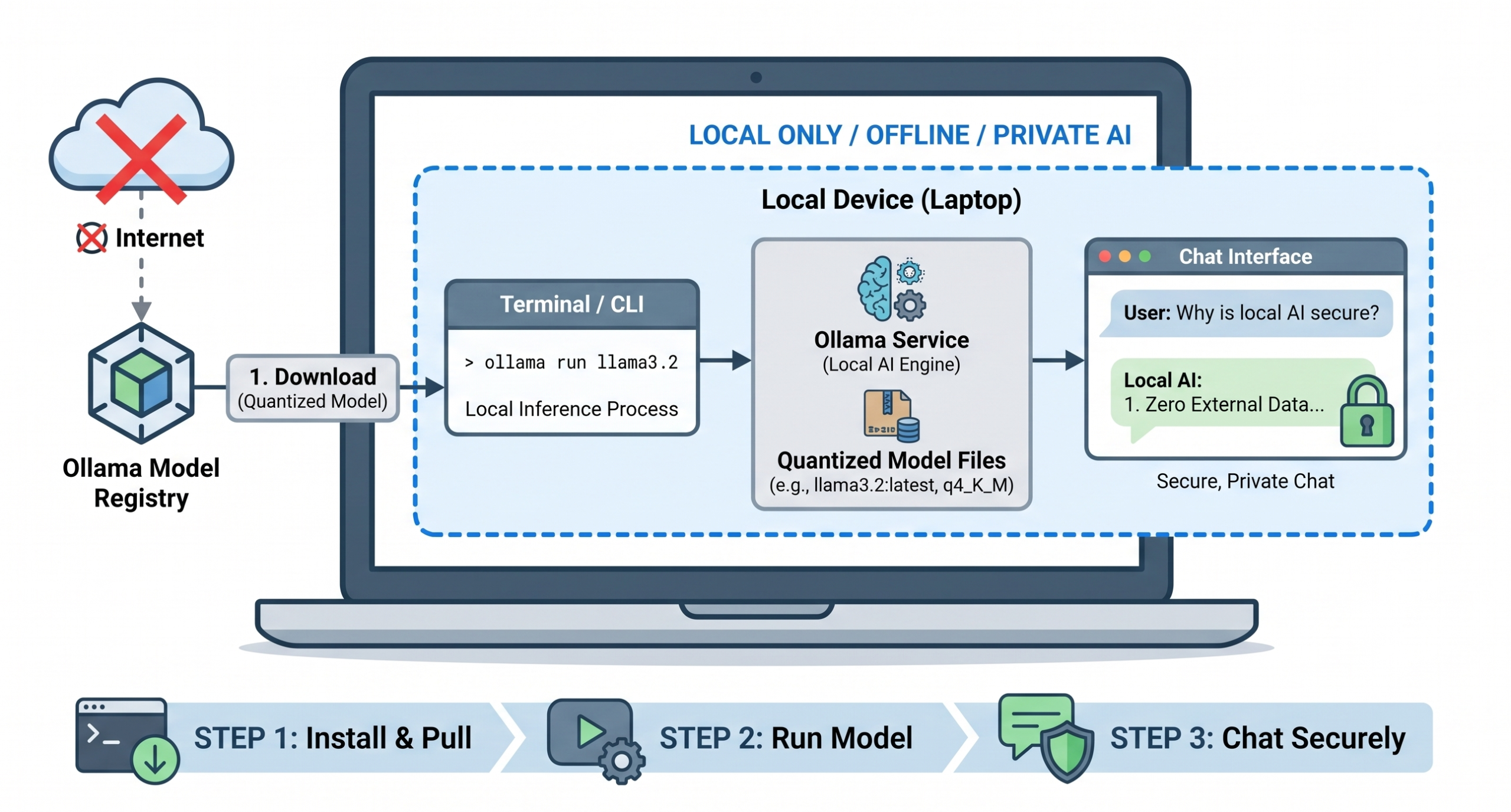
In this article, you will learn how to get a small language model running locally on your own machine in under 15 minutes using Ollama....

In this article, you will learn how scikit-ollama bridges the scikit-learn interface with locally running Ollama models to perform zero-shot text classification; no cloud API...

In this article, you will learn how to evaluate LLM applications using the three dominant open-source frameworks — RAGAS, DeepEval, and Promptfoo — and why...

Agent systems change constantly in production.
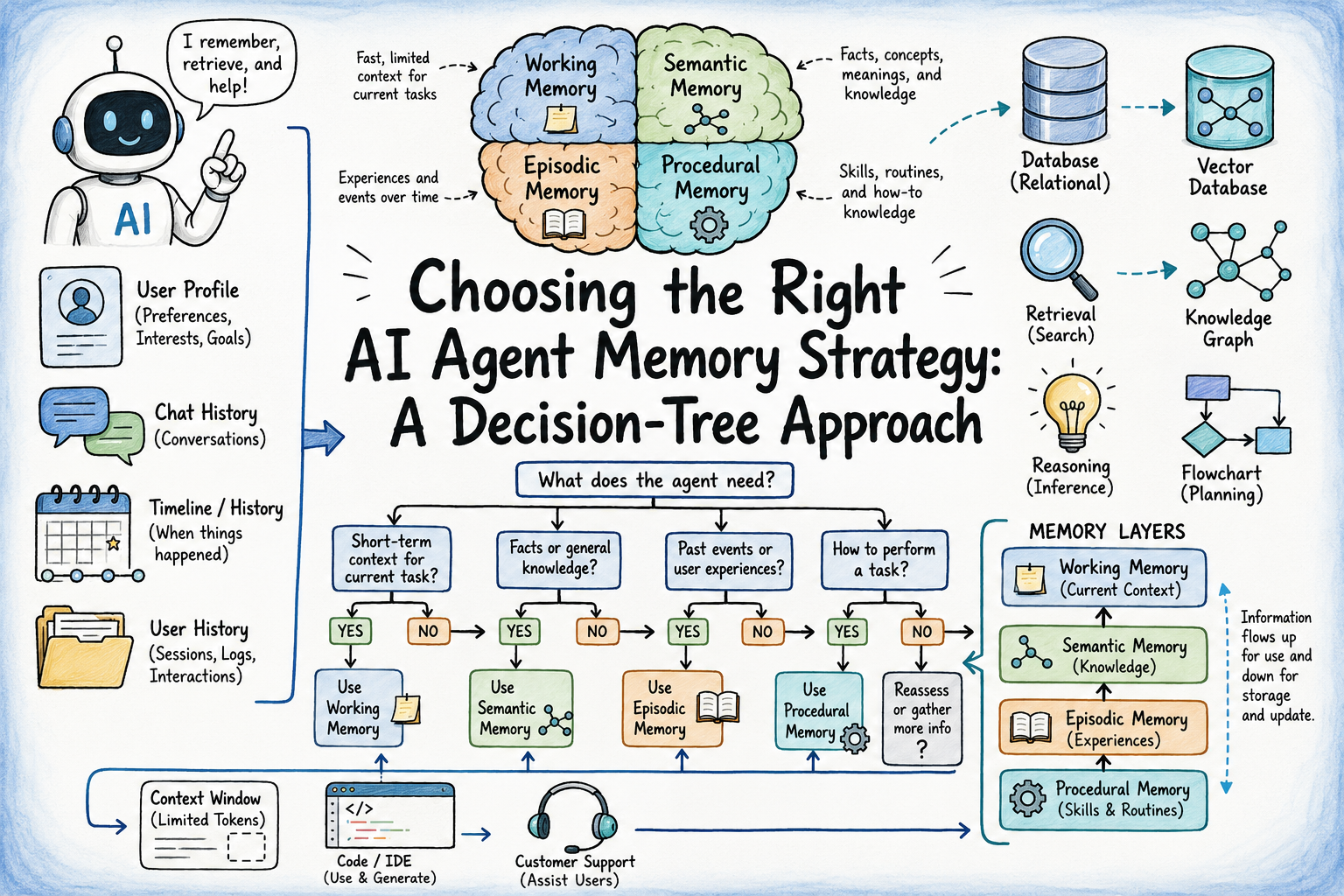
In this article, you will learn how to choose the right memory strategy for an AI agent by working through a simple decision tree, one...

The default assumption in most LLM developer communities is that you start with raw API calls and graduate to a framework as your project grows.
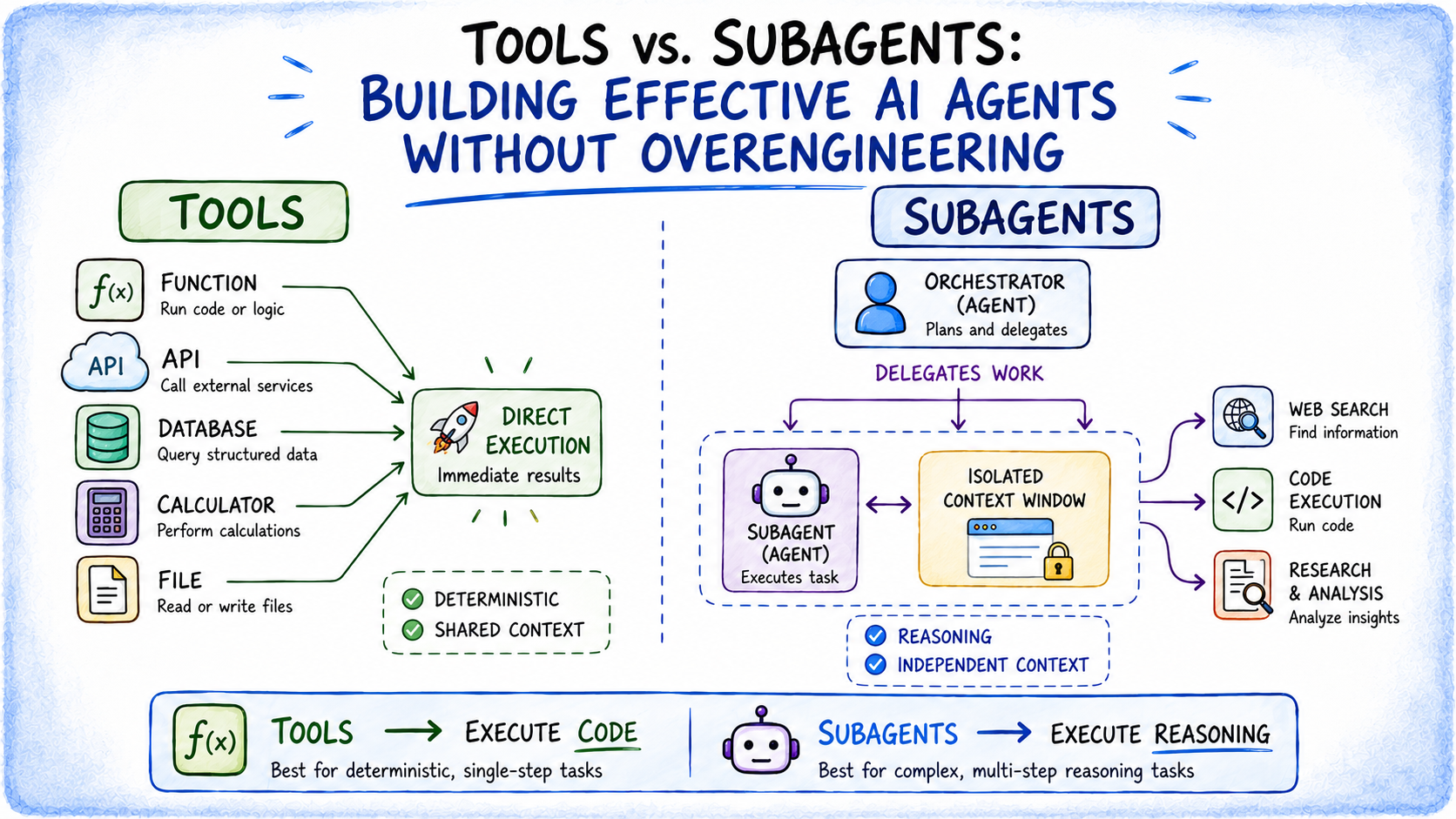
Tools execute code.
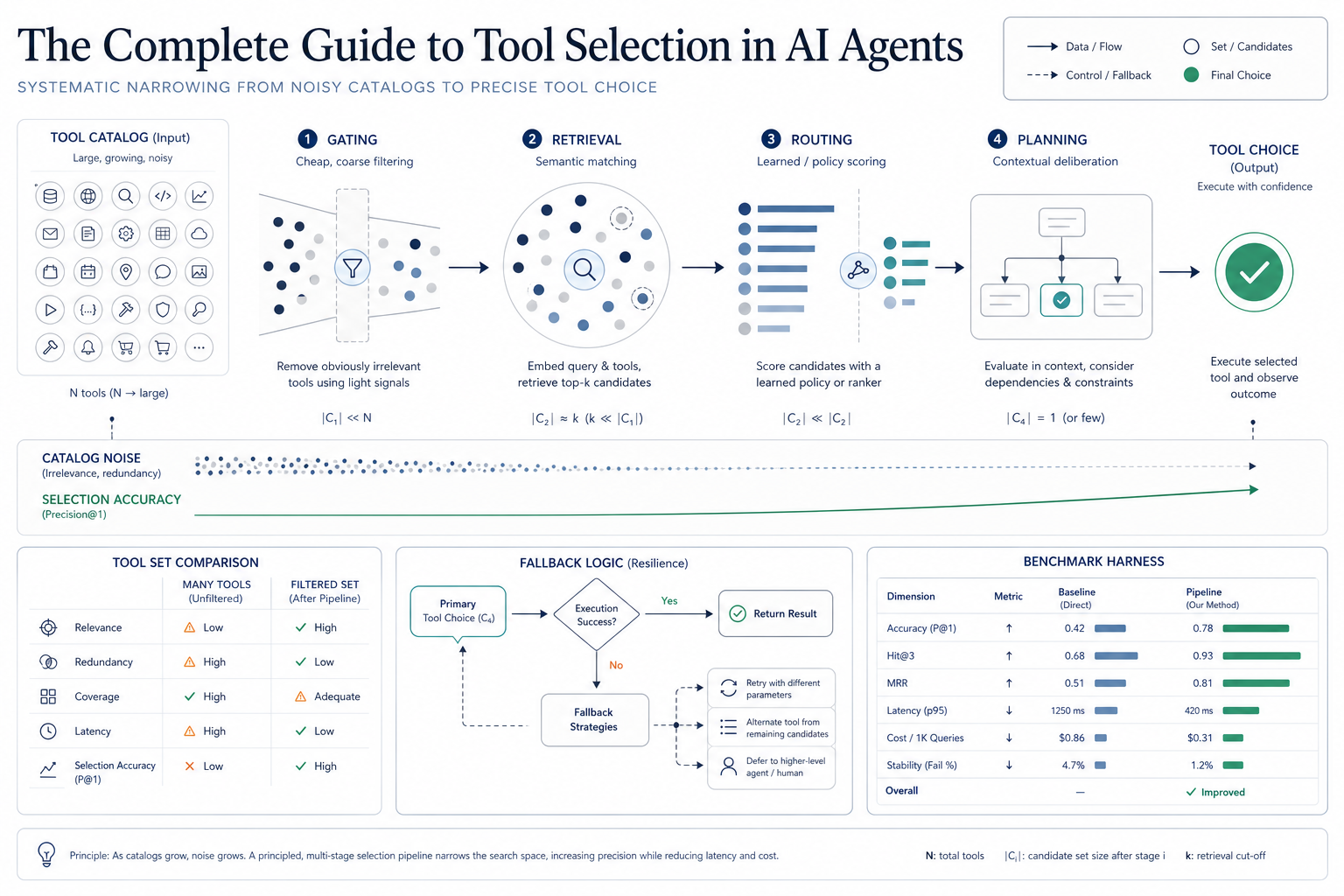
You build an agent with five tools.
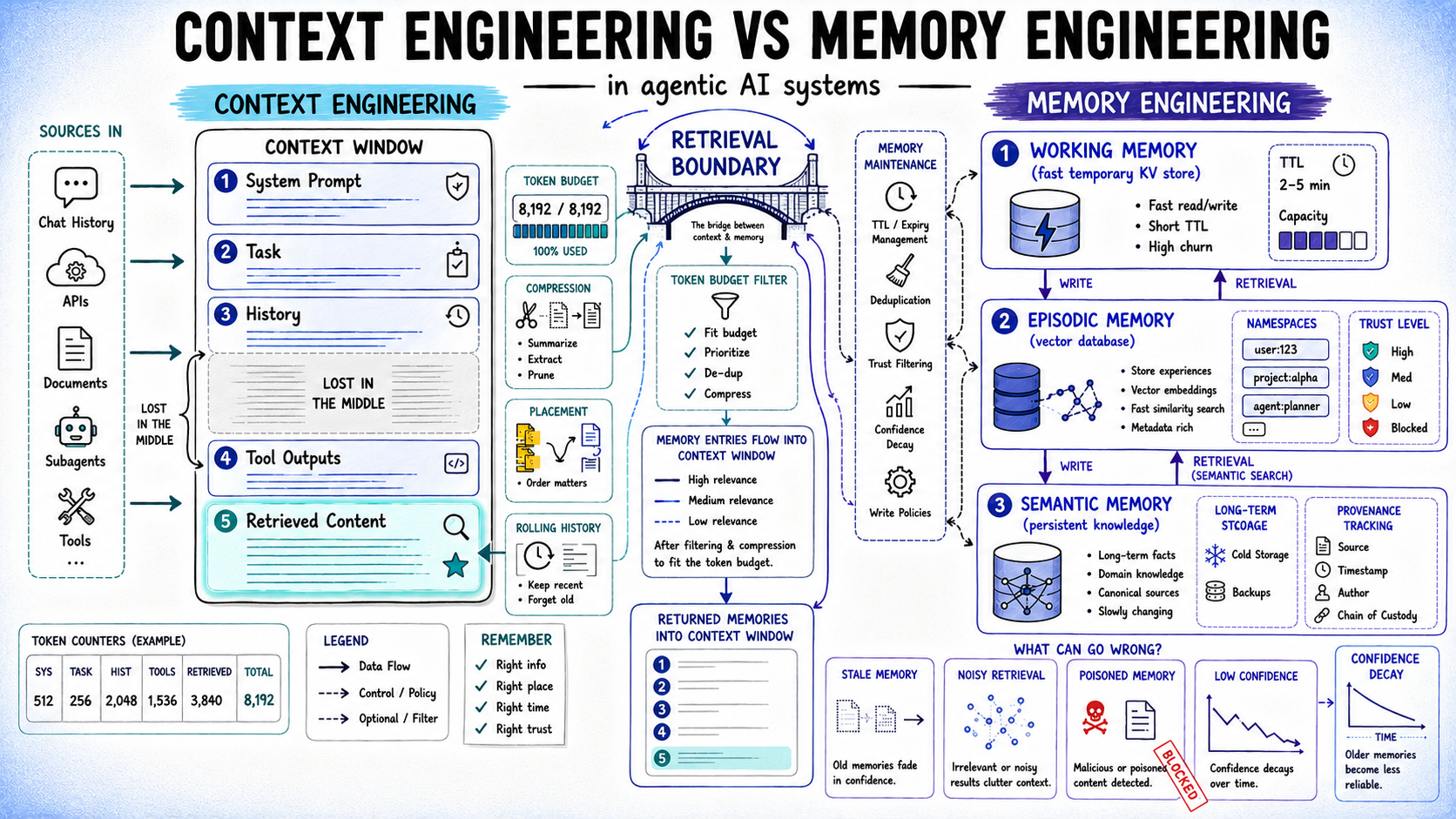
Compression on Arrival Tool outputs should be compressed after a call returns, not after the window fills.

In this article, you will learn five practical strategies for managing context windows in long-running AI agent applications, along with the key tradeoffs each approach...
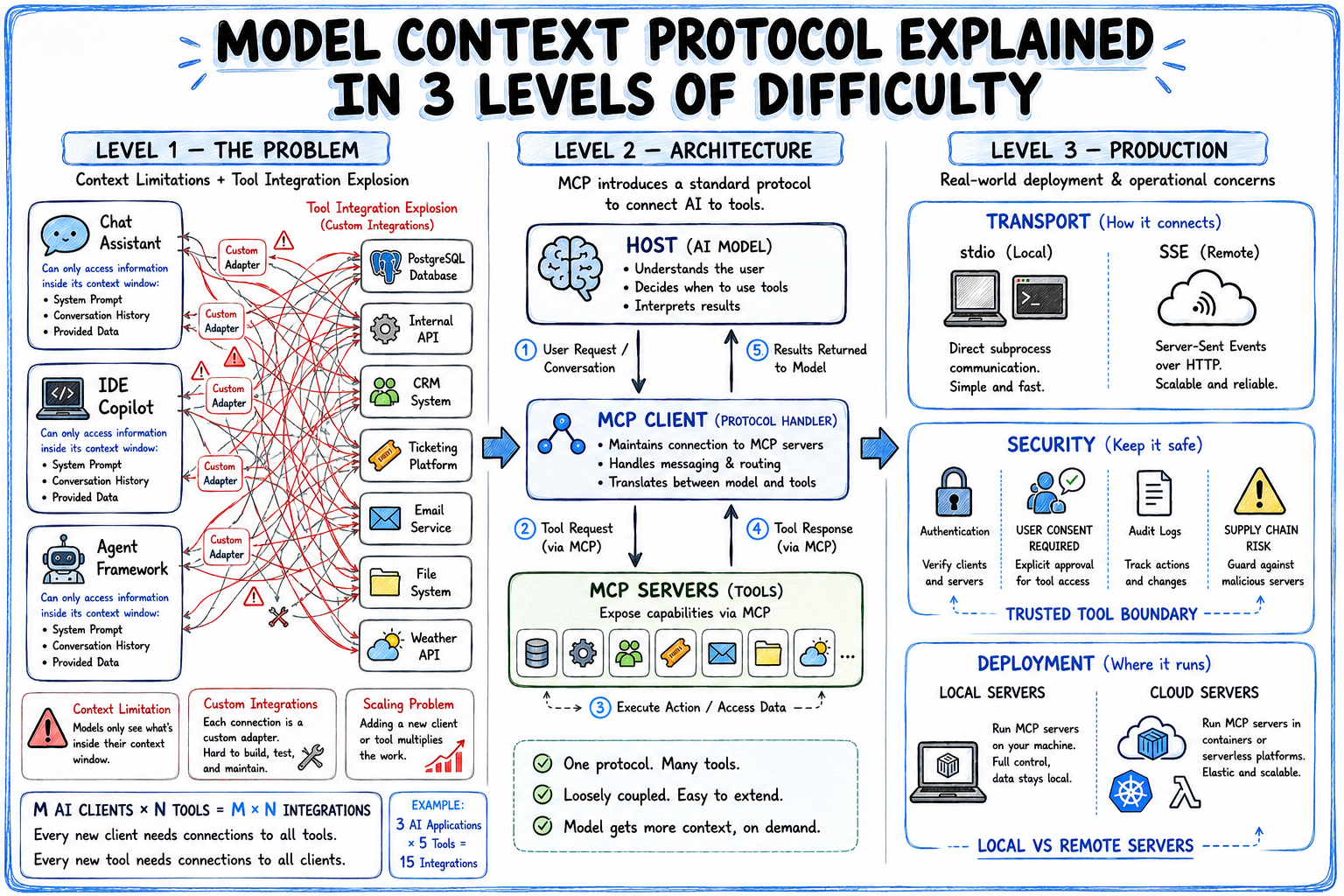
MCP provides a standard way for AI applications and external systems to communicate.

• <a href="https://www.

In this article, you will learn how to distinguish agentic workflows from autonomous agents by focusing on who owns control flow — a human writing...

In this article, you will learn why a large context window is not the same thing as agent memory, and how techniques like retrieval, compression,...